Conceitos de Inteligência Artificial e Machine Learning
Prof. Jodavid Ferreira
UFPE
Inteligência Artificial
A Inteligência, mais especificamente inteligência humana é um termo interessante de discutir, ela envolve (Sternberg, 2000):
o cérebro humano, que é o órgão mais complexo do corpo humano;
a mente, sendo esta relacionada a capacidade de pensar, raciocinar, lembrar, entender e sentir;
o pensamento lógico, que é a capacidade de raciocinar e resolver problemas;
a compreensão, associado a capacidade de entender e interpretar informações;
a aplicabilidade, que vai de encontro a capacidade de aplicar conhecimentos e habilidade em sua maioria sendo em situações práticas;
Inteligência Artificial
Independente de ser gênios da matemática ou vendedores carismáticos, nós utilizamos habilidades cognitivas como memória, atenção, reconhecimento de padrões, e outras habilidades para entender e ter sucesso no mundo todos os dias.
Em geral, a inteligência pode ser bem definida como a capacidade de um indivíduo realizar tarefas efetivamente usando seu próprio conhecimento, interpretação e perspicácia.
O nível de inteligência varia de pessoa para pessoa em termos de como percebem e realizam ações.
Inteligência Artificial
O conceito de IA está disponível desde a década de 1940 (Newell, 1982);
O primeiro método de computação baseado em “inteligência” foi introduzido pelo matemático Alan Turing em 1947. Ele afirmou que mais descobertas sobre a inteligência das máquinas poderiam ser obtidas usando programas de computador e simulação;
Inteligência Artificial
Durante a década de 1950, Turing também discutiu as circunstâncias para considerar uma máquina tão inteligente como um humano. Ele opinou fortemente que qualquer máquina pode ser capaz de imitar e fingir que é um ser humano para outro humano, sem deixar dúvidas, e assim ser considerado inteligente.
Esse conceito de testar a inteligência da máquina, introduzido por Alan Turing, é conhecido como o Teste de Turing.
Qualquer máquina que complete com sucesso o Teste de Turing pode ser considerada inteligente, mas uma máquina extraordinariamente inteligente pode sempre imitar humanos mesmo sem conhecer muito sobre eles.
Inteligência Artificial
O que é o Teste de Turing?
Turing propôs seu conceito por meio do jogo chamado “party test”, também conhecido como “teste de imitação”
O conceito básico deste jogo é descobrir se o participante é humano ou um computador.
O cenário 1 do teste consiste em três jogadores, onde o primeiro jogador é um “homem”, o segundo jogador é uma “mulher” e o terceiro jogador é o “interrogador”, que pode ser tanto um homem quanto uma mulher. Os dois primeiros jogadores estarão em salas diferentes, e o interrogador não sabe quem são os jogadores. Agora, o desafio do interrogador é descobrir o gênero dos dois primeiros jogadores com base nas respostas escritas dadas por eles para as perguntas feitas pelo interrogador. Outro desafio será criado fazendo com que o primeiro jogador dê intencionalmente respostas incorretas às perguntas, o que pode induzir o interrogador a inferir que o primeiro jogador é uma “mulher” em vez de um “homem”. A Figure 1 mostra o cenário do teste de imitação.
Figure 1: Cenário 1 no Teste de Turing.
Inteligência Artificial
O que é o Teste de Turing?
Turing tentou projetar este jogo com uma pequena alteração, na qual substituiu um dos dois primeiros jogadores por um computador no cenário de teste 2.
Ele analisou se a máquina tinha a capacidade de agir como um jogador humano aplicando sua própria inteligência.
Ele provou através do teste que o computador tem uma melhor capacidade de confundir o interrogador com sua inteligência, de modo que o interrogador tem a possibilidade de interpretar erroneamente o primeiro jogador como humano em vez de computador.
A inteligência da máquina foi comprovada através do teste de Alan Turing e amplamente aceita pela comunidade de pesquisa na época.
Figure 2: Cenário 2 no Teste de Turing.
Inteligência Artificial
Entretanto, o termo “Inteligência Artificial” efetivamente cunhado por John McCarthy em 1956, em uma conferência no Dartmouth College, marcando o início de uma nova era nos estudos de pesquisa em IA (McCorduck and Cfe, 2004).
E com esse novo termo e ramo de pesquisa, os objetivos estavam/estão à missão de usar computadores e a ciência para estudar e reproduzir a inteligência e as habilidades de tomadas de decisão associadas a um ser humano.
Assim, a utilização da IA é investigar a viabilidade de máquinas simularem aspectos do intelecto humano através de modelos computacionais e algoritmos, que foram impulsionadas pelos trabalhos de pesquisadores como Turing, Shannon, McCarthy, Minsky, entre outros.
Inteligência Artificial
Timeline 1 da IA.(fonte:Weijermars, et.al. )
Inteligência Artificial
Timeline 2 da IA.(fonte: Momentum Works report – The future by ChatGPT)
Inteligência Artificial
(fonte: AI Experience - Google)
Inteligência Artificial
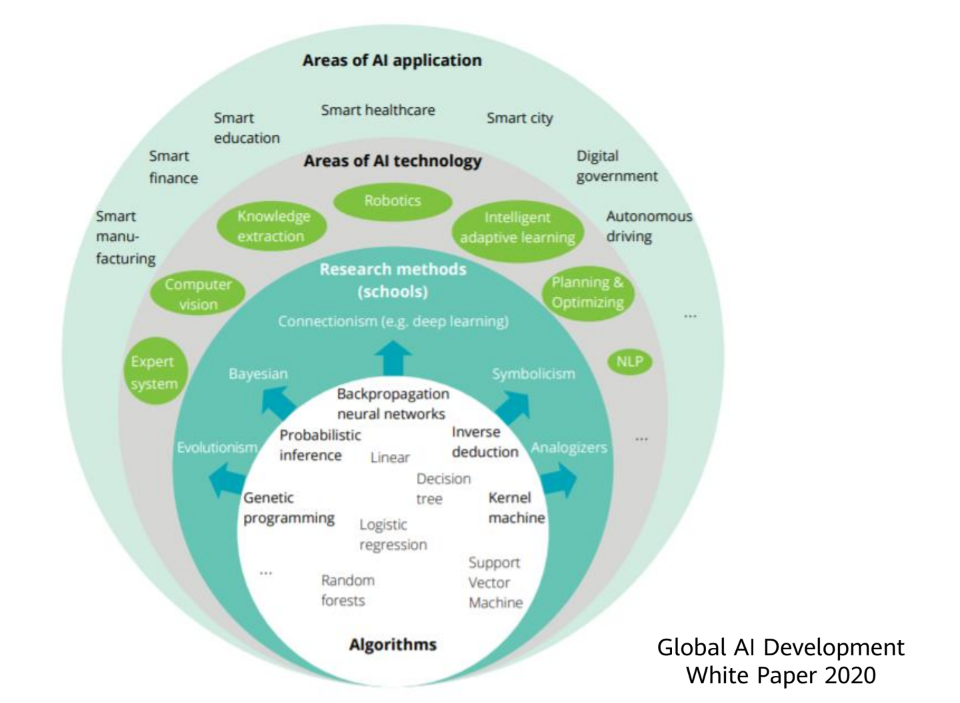
Existem três abordagens da Inteligência Artificial:
Behaviorismo
é uma escola de pensamento que diz que a inteligência depende da percepção e da ação. Assim, o comportamento da inteligência só pode ser demonstrado no mundo real através da constante interação com o meio.
IA Simbólica
tenta replicar a inteligência humana, como a capacidade de resolver problemas através de regras e lógica. Por meio de símbolos, como palavras e conceitos, uma estrutura lógica é organizada que permite ao sistema de IA realizar as tarefas.
IA Conexionista
é baseada na simulação dos componentes do cérebro (modelagem da inteligência humana), como neurônios e sinapses. Aqui as soluções são baseadas em padrões e aprendizado de máquina, tentando imitar o funcionamento do cérebro humano.
Inteligência Artificial
Exemplo de Behaviorismo: Aprendizado por reforço (Reinforcement Learning)
Exemplo de IA Simbólica: Sistemas Especialistas
Exemplo de IA Conexionista: Redes Neurais - CNN
Inteligência Artificial
A Inteligência Artificial é dividida em duas partes:
Inteligência Artificial Geral ou IA Forte
é quando uma máquina realmente entende o que está acontecendo. Podem existir emoções e criatividade. Na maior parte, é o que vemo em filmes de ficção científica.
IA Fraca
é quando uma máquina realiza a correspondência entre padrões, e está relacionada a tarefas específicas, e as capacidades não são facilmente transferíveis para outros sistemas.
Inteligência Artificial
Inteligência Artificial
Machine Learning
Deep Learning
IA Generativa
Inteligência Artificial
Inteligência Artificial
Machine Learning
Deep Learning
IA Generativa
Ambiente da IA
O ambiente de inteligência artificial consiste em cinco componentes principais:
Máquina: é um componente básico e implícito tanto em ambientes não baseados em IA quanto em ambientes baseados em IA;
Inteligência Humana: esse componente é essencial para incorpor ‘inteligência’ à máquina, para que ela atue como uma máquina inteligente carregando inteligência humana, na forma de uma lista de instruções também chamada de programas, softwares ou codificação;
Internet das Coisas (IoT): Atualmente, a Internet das Coisas (IoT) têm uma relação muito próxima com o ambiente de IA, uma vez que a maioria das atuais tomadas de decisão dependem dos dados que são produzidos em tempo real pelos humanos e pelas máquinas;
Algoritmos de Aprendizado de Máquina (ML): algoritmos de aprendizado de máquina desempenham um papel importante, na IA. Esses algoritmos são muito úteis na previsão de eventos com base nos dados disponíveis. Dentres os tipos de aprendizados estão os supervisionados (Regressão, Classificação), não supervisionados (métodos de agrupamento, redução de dimensionalidade), entre outros.
Ciência e Engenharia de Dados: A Ciência e Engenharia de Dados é outro componente importante no ambiente de IA. A análise de dados desempenha um papel importante na maioria das aplicações em tempo real, pois qualquer tomada de decisão feita pela máquina por meio de programação depende principalmente da análise eficiente de dados.
Ambiente da IA
O ambiente de inteligência artificial consiste em cinco componentes principais:
Máquina: é um componente básico e implícito tanto em ambientes não baseados em IA quanto em ambientes baseados em IA;
Inteligência Humana: esse componente é essencial para incorpor ‘inteligência’ à máquina, para que ela atue como uma máquina inteligente carregando inteligência humana, na forma de uma lista de instruções também chamada de programas, softwares ou codificação;
Internet das Coisas (IoT): Atualmente, a Internet das Coisas (IoT) têm uma relação muito próxima com o ambiente de IA, uma vez que a maioria das atuais tomadas de decisão dependem dos dados que são produzidos em tempo real pelos humanos e pelas máquinas;
Algoritmos de Aprendizado de Máquina (ML): algoritmos de aprendizado de máquina desempenham um papel importante, na IA. Esses algoritmos são muito úteis na previsão de eventos com base nos dados disponíveis. Dentres os tipos de aprendizados estão os supervisionados (Regressão, Classificação), não supervisionados (métodos de agrupamento, redução de dimensionalidade), entre outros.
Ciência e Engenharia de Dados: A Ciência e Engenharia de Dados é outro componente importante no ambiente de IA. A análise de dados desempenha um papel importante na maioria das aplicações em tempo real, pois qualquer tomada de decisão feita pela máquina por meio de programação depende principalmente da análise eficiente de dados.
Machine Learning
Machine Leaning (ML) ou Aprendizado de máquina (AM) é um subcampo da Inteligência Artificial que estuda, desenvolve e analisa os algoritmos de aprendizado. Através de utilização dos métodos de AM, modelos baseado em dados podem ser criados para solucionar um determinado tipo de problema específico que de IA, dentre eles, aprendizados supervisionados, não supervisionados e aprendizagem por reforço.
Machine Learning
Inicialmente, as aplicações que eram consideradas de AM eram apenas as desenvolvidas estritamente pela comunidade da computação, contudo, no final dos anos 90, as aplicações de AM começaram a ter intersecções com as de estatística.
Atualmente, a comunidade de AM é bastante interdisciplinar, sendo a estatística uma das áreas. Enquanto que até os anos 90, métodos criados pela estatística começavam a ser incorporados em AM, atualmente a direção oposta está cada vez mais comum: métodos desenvolvidos por AM começaram a ser usados em estatística.
Dessa forma, hoje os algoritmos existentes em Machine Learning e Inteligência Artificial possuem como base em sua maioria conceitos da Estatística e Computação.
Machine Learning
O machine learning assume muitas formas e é conhecido por muitos nomes:
reconhecimento de padrões
modelagem estatística
mineração de dados
descoberta de conhecimento
análise preditiva
ciência de dados
sistemas adaptativos
sistemas auto-organizados
Alguns terão vida longa, outros durarão menos.
Machine Learning
O machine learning às vezes é confundido com IA, mas como já sabem, ele é um subcampo da IA, entretanto, cresceu tanto e foi tão bem-sucedido que ofusca sua orgulhosa mãe.
Inteligência Artificial
Machine Learning
Deep Learning
Machine Learning
O machine learning às vezes é confundido com IA, mas como já sabem, ele é um subcampo da IA, entretanto, cresceu tanto e foi tão bem-sucedido que ofusca sua orgulhosa mãe.
Inteligência Artificial
Machine Learning
Deep Learning
Machine Learning
Formulação Geral
A função \(f\) é desconhecida. Representa a solução IDEAL.
Os algoritmos de ML buscan uma função \(g \approx f\).
Machine Learning
Conceitos importantes incluem:
Aprendizado supervisionado - algoritmos treinados com dados rotulados, mapeando entradas para saídas desejadas.
Aprendizado não supervisionado - algoritmos que clusterizam e fazem inferências sobre conjuntos de dados não rotulados.
Aprendizado por reforço - algoritmos que aprendem com tentativa e erro interagindo com um ambiente dinâmico.
Machine Learning
Conceitos importantes incluem:
Aprendizado supervisionado - algoritmos treinados com dados rotulados, mapeando entradas para saídas desejadas.
Aprendizado não supervisionado - algoritmos que clusterizam e fazem inferências sobre conjuntos de dados não rotulados.
Aprendizado por reforço - algoritmos que aprendem com tentativa e erro interagindo com um ambiente dinâmico.
Aprendizado supervisionado - ML
Aprendizado supervisionado
O aprendizado supervisionado é o tipo mais comum de aprendizado de máquina. Ele é usado para prever um resultado com base em um conjunto de variáveis de entrada.
O aprendizado supervisionado é chamado assim porque o algoritmo aprende a partir de um conjunto de dados rotulados, ou seja, um conjunto de dados que contém entradas e saídas desejadas.
O aprendizado supervisionado é usado em uma ampla variedade de aplicações, incluindo classificação, regressão.
Aprendizado supervisionado - ML
Quando a saída desejada é uma variável qualitativa \((y \in \mathbb{R})\), o problema é chamado de CLASSIFICAÇÃO.
Obtém um modelo otimizado por meio de treinamento e aprendizado baseado em observações \(x_i\), com \(i = 1, 2, \ldots, N\), para as quais se tem a respectiva resposta \(y_i\) desejada.
Cada observação \(x_i\) pode ser formada por \(n\)variáveis (features) independentes \(x_{i1}, x_{i2}, \ldots, x_{in}\), com \(n \geq 1\).
Aprendizado supervisionado - ML
O objetivo é usar o modelo criado para mapear novas entradas.
Quando a saída desejada é referentes a uma variável quantintativa seja essa, pertencente aos números inteiros \((y \in \mathbb{Z})\) ou aos números reais \((y \in \mathbb{R})\), o problema é chamado de REGRESSÃO.
Por exemplo:
Qual o peso médio dos jogadores de futebol?
Qual a temperatura média em Recife no mês de Junho?
Quanto vale um apartamento de \(100m^2\) em Boa Viagem?
Aprendizado não supervisionado - ML
Aprendizado não supervisionado
O aprendizado não supervisionado é o tipo de aprendizado de máquina que é usado para fazer inferências a partir de conjuntos de dados não rotulados.
O aprendizado não supervisionado é chamado assim porque o algoritmo não é treinado com dados rotulados. Em vez disso, o algoritmo aprende com os dados de treinamento e é capaz de fazer inferências sobre novos dados.
O aprendizado não supervisionado é usado em uma ampla variedade de aplicações, incluindo clusterização, redução de dimensionalidade.
Aprendizado não supervisionado - ML
Obtém um modelo otimizado processando diretamente os dados de entrada, sem conhecer a saída desejada. Novamente, temos um conjunto de observações \(x_i\), com \(i = 1, 2, \ldots, N\) e \(n\) features.
Aprendizado não supervisionado - ML
Clusterização é a técnica de aprendizado não supervisionado mais comum. Ela é usada para agrupar dados em grupos com base em suas características (variáveis, features)
Novas observações podem ser agrupadas calculando sua semelhança em relação aos demais grupos formados.
Aprendizado por reforço - ML
Dentre os três tipos apresentados, é a área mais “próxima” da IA em termos de “borda de conhecimento.
Representa uma quebra de paradigma, pois não depende de receber a resposta certa, nem de buscar semelhanças entre amostras. Buscar “recompensas” que são obtidas quando “bons” resultados são obtidos.
Intuitivamente, o diferencial é claro:
O algoritmo pode aprender além da informação que consta na base de dados.
Aprendizado por reforço - ML
No lugar da amostra, temos uma sequência de ações que são tomadas em um ambiente, e o algoritmo aprende a melhor sequência de ações para maximizar uma recompensa.
Para cada ação, há um feedback que indica se a ação foi boa ou ruim.
Por exemplo: Após várias jogadas, ganhou o jogo de damas.
Aprendizado por reforço - ML
Objetivo é o algoritmo controlar o braço robótico e aprender a chegar no ponto vermelho.
ML: Processo de Aprendizagem
Figure 3
Observe que o processo é iterativo, ou seja, é necessário voltar a etapas anteriores para ajustar o modelo.
ML: Processo de Aprendizagem
Organização dos dados
Dataset: designa amplamente os dados usados no aprendizado de máquina. Cada registro é nomeado de observação, exemplo, instância ou amostra (sample), a qual é formada por variáveis ou características (features). “Features” são partes relevantes para caracterizar as observações.
Conjunto de treinamento (training set): é o conjunto de dados usado para treinar o modelo (aprendizado). É formado por um conjunto de observações e suas respectivas saídas desejadas.
Conjunto de teste (test set): é o conjunto de dados usado para avaliar o modelo treinado. Simula a situação real, onde o modelo é aplicado a novos dados. É formado por um conjunto de observações de entrada.
ML: Processo de Aprendizagem
Exemplo de “dataset” (dados rotulados):
ML: Processo de Aprendizagem
Exemplo de “dataset” (dados rotulados):
ML: Processo de Aprendizagem
Importância dos Dados
Se os dados forem bons, não há como garantir que o modelo será bom
Se os dados não são bons, podemos garantir que o modelo será ruim
Etapas de Pré-processamento
Limpeza\(\rightarrow\) Remoção de dados duplicados, outliers, dados faltantes, evita incosisntências e erros na leitura dos dados;
Redução dimensional\(\rightarrow\) evitar explosão dimensional, reduzindo o número de variáveis;
Normalização\(\rightarrow\) padronização dos dados, evitando que variáveis com escalas diferentes influenciem o modelo, reduz ruídos e melhora a performance do modelo;
ML: Processo de Aprendizagem
O Processo começa pela limpeza dos dados, mas observe a divisão do trabalho relatada por cientistas de dados…
ML: Processo de Aprendizagem
Limpeza dos Dados
Geralmente, os modelos de aprendizado de máquina não funcionam bem com dados faltantes, duplicados ou inconsistentes.
É comum ter dados coletados que só podem ser usados após uma etapade preparação que pode incluir:
Remoção de dados duplicados;
Tratamento de dados faltantes;
Tratamento de outliers;
Normalização dos dados;
Redução de dimensionalidade;
Transformação de variáveis categóricas em numéricas;
Balanceamento de classes;
ML: Processo de Aprendizagem
Exemplos de problemas vistos em dados brutos:
ML: Processo de Aprendizagem
Conversão de dados
A etapa de conversão ocorre entre o pré-processamento e a etapa de selação de variáveis e consiste em converter os dados para o formato adequado para o modelo.
Por exemplo:
Conversão de variáveis categóricas em numéricas;
Conversão de variáveis numéricas em categóricas;
Conversão de variáveis temporais em numéricas;
Conversão de variáveis textuais em numéricas (word embedding, word2vec, BERt, etc.);
Conversão de imagens em numéricas;
Conversão de áudio em numéricas;
ML: Processo de Aprendizagem
Conversão de dados
Dados de imagens podem ser transformados…
Espaço de cores;
Escala de cinza;
Histograma de cores;
Transformada de Fourier;
Feature Engineering: criação de novas variáveis a partir das variáveis originais.
Normalização de características para igualar “range” de valores;
Expansão de características: combinar ou converter variáveis para gerar novas características;
ML: Processo de Aprendizagem
Após limpeza e conversão…
Seleção de características (Feature Selection) \(\rightarrow\) Motivações
Geralmente, há um grande número de “features” nas bases de dados. Algumas podem ser rendundantes ou irrelevantes para a previsão que se deseja fazer, podendo ser desprezadas.
Essa etapa independe do algorito de aprendizagem de máquina.
Há quatro motivações para implementar a seleção de “features”.
ML: Processo de Aprendizagem
Seleção de características (Feature Selection) \(\rightarrow\) Métodos
Destacamos três conjuntos de métodos:
Filtros: métodos que selecionam “features” com base em métricas estatísticas, como correlação, entropia, etc.
Wrappers: métodos que selecionam “features” com base no desempenho de um modelo de aprendizado de máquina.
Embedded: métodos que selecionam “features” durante o treinamento do modelo.
ML: Processo de Aprendizagem
Seleção de características (Feature Selection) \(\rightarrow\) Filtro
Engloba técnicas baseadas na correlação entre as “features” e a variável alvo.
Geralmente, usam parâmetros estatísticos para selecionar as “features” mais relevantes, através de um limiar, ou seja, um “rank” das “features”.
ML: Processo de Aprendizagem
Seleção de características (Feature Selection) \(\rightarrow\) Filtro
Métodos Comuns:
Correlação de Pearson: mede a relação linear entre duas variáveis contínuas.
Correlação de Spearman: mede a relação monotônica entre duas variáveis contínuas ou ordinais.
Correlação de Kendall: mede a relação ordinal entre duas variáveis ordinais.
Teste Qui-Quadrado: mede a relação entre duas variáveis categóricas.
Limitações:
Não considera a relação entre as “features”;
Não considera a relação não linear entre as “features” e a variável alvo;
Não considera a relação entre as “features” e a variável alvo.
ML: Processo de Aprendizagem
Seleção de características (Feature Selection) \(\rightarrow\) Wrapper
Engloba técnicas que usam um modelo de aprendizado de máquina para avaliar a importância das “features”.
Geralmente, usam um modelo de aprendizado de máquina para avaliar a importância das “features” e selecionar as mais relevantes.
ML: Processo de Aprendizagem
Seleção de características (Feature Selection) \(\rightarrow\) Wrapper
Métodos Comuns:
Seleção para Frente (Forward): começa com um modelo vazio e adiciona uma “feature” por vez, avaliando o desempenho do modelo a cada iteração.
Seleção para Trás (Backward): começa com todas as “features” e remove uma “feature” por vez, avaliando o desempenho do modelo a cada iteração.
Seleção para Frente e para Trás (Stepwise): combina as duas técnicas anteriores.
Eliminação Recursiva de “Features” (RFE): remove “features” de acordo com a importância atribuída pelo modelo.
Limitações:
Alto custo computacional;
Pode ser sensível a ruídos;
Pode ser sensível a overfitting.
ML: Processo de Aprendizagem
Seleção de características (Feature Selection) \(\rightarrow\) Embedded
Engloba técnicas em que a seleção de “features” é incorporada ao treinamento do modelo.
A forma mais comum de seleção de “features” incorporada é a regularização.
ML: Processo de Aprendizagem
Seleção de características (Feature Selection) \(\rightarrow\) Embedded
Métodos Comuns:
Lasso (Least Absolute Shrinkage and Selection Operator): adiciona um termo de penalização L1 à função de custo.
Ridge: adiciona um termo de penalização L2 à função de custo.
Random Forest, XGBoost, LightGBM, CatBoost: avalia a importância das “features” com base na redução da impureza, ou seja, a importância das “features” é avaliada durante o treinamento do modelo.
Limitações:
Pode ser sensível a overfitting;
Pode ser sensível a ruídos.
ML: Processo de Aprendizagem
Seleção de características (Feature Selection) \(\rightarrow\) Embedded
Regularização L1 (Lasso):
São também nomeados de métodos de penalização L1, pois adicionam um termo de penalização L1 à função de custo. Este método, introduz restrições no processo de otimização do modelo, forçando os coeficientes de algumas “features” a zero, eliminando-as do modelo.
Por exemplo: pesos de features redundantes se anulam naturalmente…
ML: Processo de Aprendizagem
Resumo geral da construção de um Modelode 1 até 6… Observe 2!
ML: Processo de Aprendizagem
Um exemplo de Aprendizado Supervisionado \(\rightarrow\) Etapa de Aprendizado
ML: Processo de Aprendizagem
Um exemplo de Aprendizado Supervisionado \(\rightarrow\) Etapa de Aprendizado
ML: Processo de Aprendizagem
Um exemplo de Aprendizado Supervisionado \(\rightarrow\) Etapa de Previsão
ML: Processo de Aprendizagem
O que define um modelo como bom?
Quais são as perguntas certas?
Precisão: o modelo está prevendo corretamente? ou seja, a acurácia do modelo é alta.
Interpretabilidade: o modelo é compreensível? ou seja, é possível entender como o modelo chegou a uma determinada previsão.
Robustez: o modelo é resistente a ruídos? isto é, o modelo é capaz de generalizar para novos dados.
Escalabilidade: o modelo é escalável? isto é, o modelo é capaz de lidar com grandes volumes de dados.
Generalização: o modelo é generalizável? isto é, o modelo é capaz de prever corretamente para novos dados.
Eficiência: o modelo é eficiente? isto é, o modelo é capaz de prever em tempo hábil.
ML: Processo de Aprendizagem
Validade do Modelo - Definições
Capacidade de generalização: capacidade do modelo de prever corretamente para novos dados.
Erro: diferença entre o valor previsto e o valor real. Há dois tipos:
Erro de treinamento: erro entre o valor previsto e o valor real no conjunto de treinamento.
Erro de teste: erro entre o valor previsto e o valor real no conjunto de teste.
Capacidade do modelo: capacidade do modelo de se ajustar aos dados de treinamento e generalizar para novos dados.
ML: Processo de Aprendizagem
Validade do Modelo - Definições
Underfitting
Ocorre quando o modelo é muito simples para capturar a complexidade dos dados.
Ocorre quando o modelo ou algoritmo nao consegue encontrar uma relação entre as grandezas de entradae a saída.
Os erros de treinamento e de generalizações tendem a ser altos.
A capacidade do modelo é baixa.
ML: Processo de Aprendizagem
Validade do Modelo - Definições
Overfitting
Ocorre quando o modelo ou algoritmo opera perfeitamente apenas nos dados de treino.
Os erros de treinamento são baixos, mas os erros de generalização são altos.
A capacidade do modelo pode ter sido excessiva, de modo que o modelo nãoé capaz de generalizar para novos dados.
ML: Processo de Aprendizagem
Validade do Modelo - Definições
Good fitting (Ajuste adequado)
Ocorre quando o modelo ou algoritmo atende ao compromisso entre treinamento e generalização.
Os erros de treinamento e de generalização são baixos.
A capacidade do modelo é adequada.
ML: Processo de Aprendizagem
Variância e Tendência (Variance and Bias)
ML: Processo de Aprendizagem
O erro total de previsão depende da variância e do viés do modelo:
\[
\text{Erro Total} = \text{Erro de Viés} + \text{Erro de Variância} + \text{Erro Irredutível}
\]
Erro de Viés: erro devido à simplificação do modelo, ou seja, o modelo não consegue capturar a complexidade dos dados.
Erro de Variância: erro devido à complexidade do modelo, ou seja, o modelo é muito complexo e não consegue generalizar para novos dados.
Erro Irredutível: erro devido ao ruído nos dados, ou seja, o modelo não consegue prever corretamente devido ao ruído nos dados.
Erro Total: erro total de previsão, ou seja, a diferença entre o valor previsto e o valor real.
ML: Processo de Aprendizagem
Como regra geral:
Modelo bom é aquele que tem baixo erro de viés e baixo erro de variância.
Por sua origem, os erros podem ser divididos em duas categorias:
erros causados por variância;
erros causados por viés;
ML: Processo de Aprendizagem
Variância e Tendência (Variance and Bias) \(\rightarrow\) Aprendizado de Máquina
Análise qualitativa:
Variância alta significa que o modelo tem alta sensibilidade a pequenas variações no conjunto de treinamento.
Esse comportamento é compatível com overfitting!
Viés está relacionada com a diferença entre a média das previsões e os valores corretos que desejamos prever.
Esse comportamento é compatível com underfitting!
ML: Processo de Aprendizagem
Capacidade do Modelo vs Erro de Previsão \(\rightarrow\) Baixa Complexidade
Underfitting!
ML: Processo de Aprendizagem
Capacidade do Modelo vs Erro de Previsão \(\rightarrow\) Alta Complexidade
Overfitting!
ML: Processo de Aprendizagem
Capacidade do Modelo vs Erro de Previsão \(\rightarrow\) Compromisso
Good fitting!
ML: Processo de Aprendizagem
Como avaliar quantitativamente o desempenho do modelo?
Problemas de Regressão:
Erro absoluto médio (MAE): média das diferenças absolutas entre o valor previsto e o valor real.
\[MAE = \frac{1}{n} \sum_{i=1}^{n} |y_i - \hat{y}_i|\] em que, \(n\) é o número de observações, \(y_i\) é o valor real e \(\hat{y}_i\) é o valor previsto.
ML: Processo de Aprendizagem
Como avaliar quantitativamente o desempenho do modelo?
Problemas de Regressão:
Erro quadrático médio (MSE): média dos quadrados das diferenças entre o valor previsto e o valor real.
em que, \(n\) é o número de observações, \(y_i\) é o valor real e \(\hat{y}_i\) é o valor previsto.
ML: Processo de Aprendizagem
Como avaliar quantitativamente o desempenho do modelo?
Problemas de Regressão:
Coeficiente de determinação (\(R^2\)): mede a proporção da variabilidade da variável dependente que é explicada pelo modelo.
\[R^2 = 1 - \frac{\sum_{i=1}^{n} (y_i - \hat{y}_i)^2}{\sum_{i=1}^{n} (y_i - \bar{y})^2}\] em que, \(n\) é o número de observações, \(y_i\) é o valor real, \(\hat{y}_i\) é o valor previsto e \(\bar{y}\) é a média dos valores reais.
ML: Processo de Aprendizagem
Como avaliar quantitativamente o desempenho do modelo?
Problemas de Classificação:
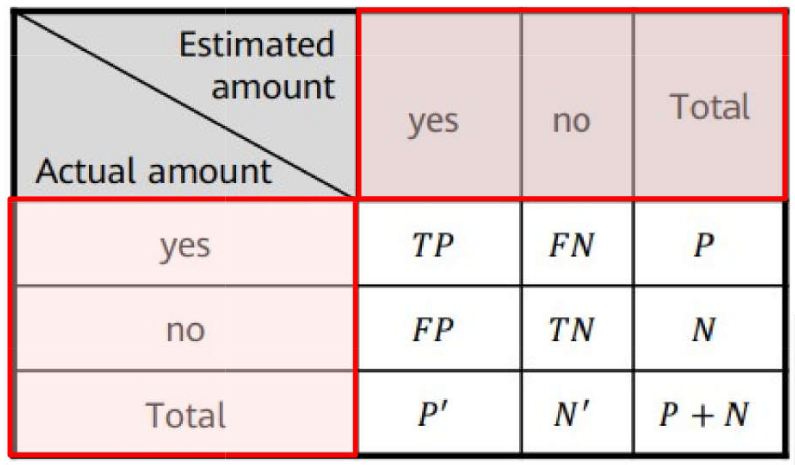
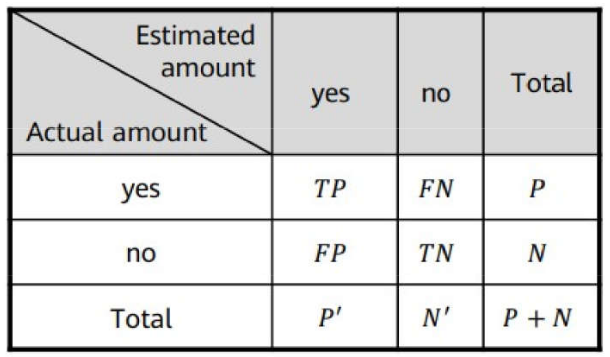
Matriz de confusão: matriz que mostra a relação entre as previsões corretas e as previsões erradas.
Supondo n = 2;
Dados reais nas linhas
Dados previstos nas colunas
ML: Processo de Aprendizagem
Como avaliar quantitativamente o desempenho do modelo?
Problemas de Classificação:
Matriz de confusão - 2 categorias;
Diagonal principal tem os acertos;
Demais elementos armazenam os erros;
P é o número correto de “yes”
P’ é o número classificado como “yes”
N é o número correto de “no”
N’ é o número classificado como “no”
ML: Processo de Aprendizagem
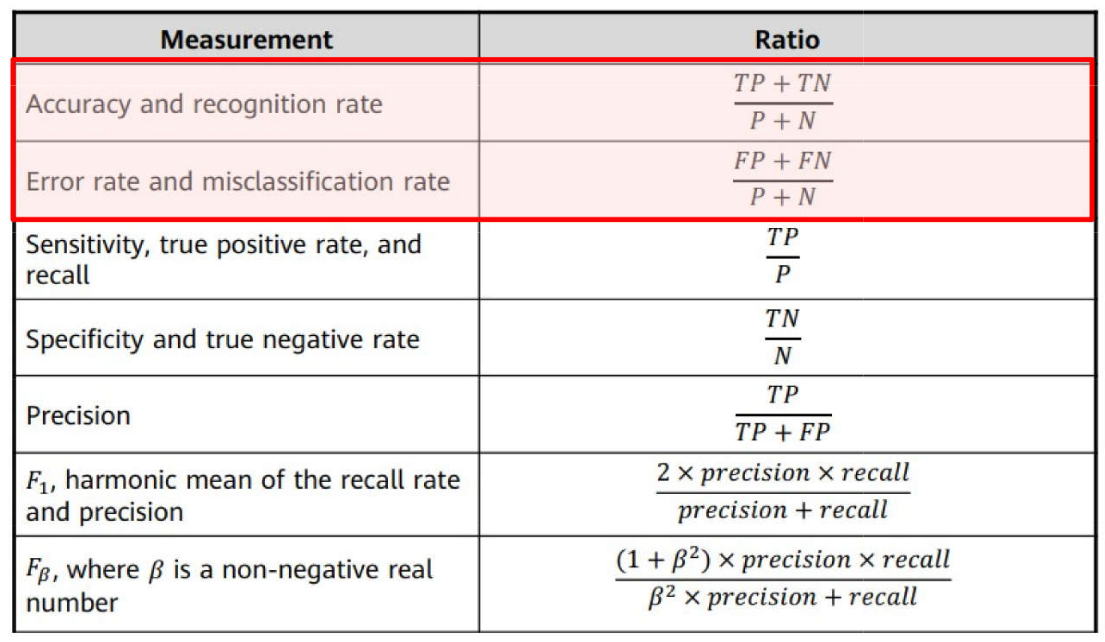
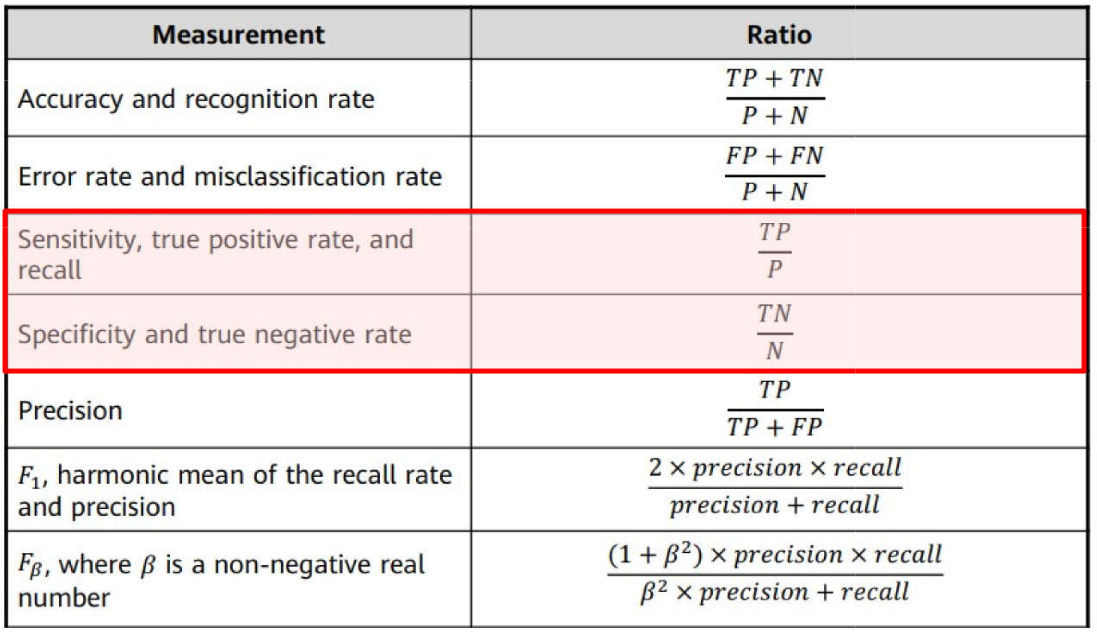
Problemas de Classificação \(\rightarrow\) Métricas: Acurácia e Taxa de Erro
ML: Processo de Aprendizagem
Problemas de Classificação \(\rightarrow\) Métricas: Sensibilidade e Especificidade
ML: Processo de Aprendizagem
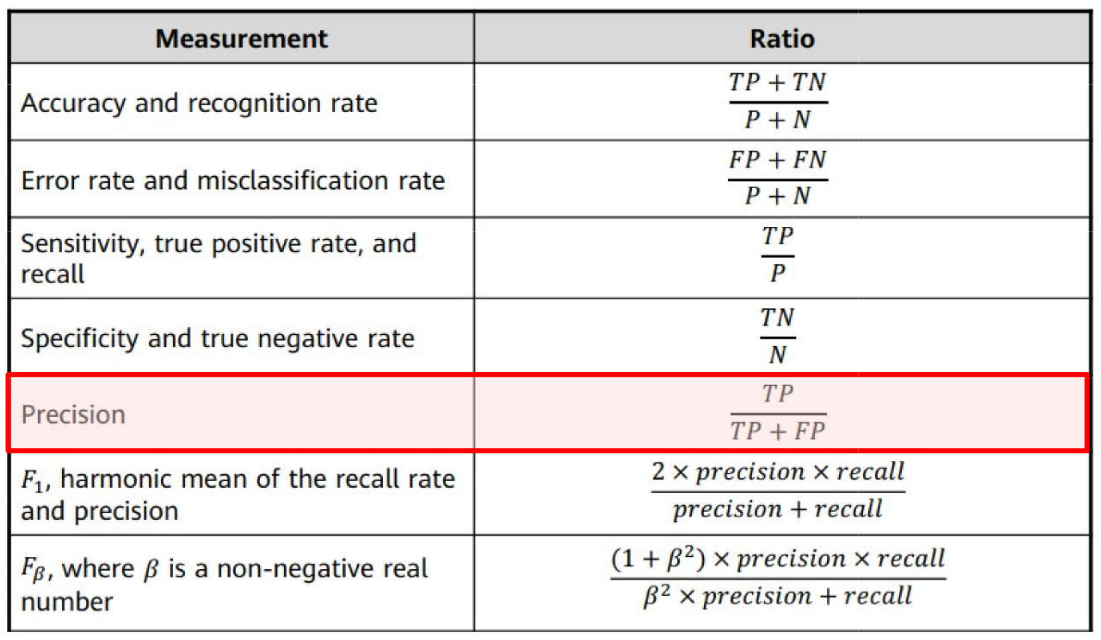
Problemas de Classificação \(\rightarrow\) Métricas: Precisão
ML: Processo de Aprendizagem
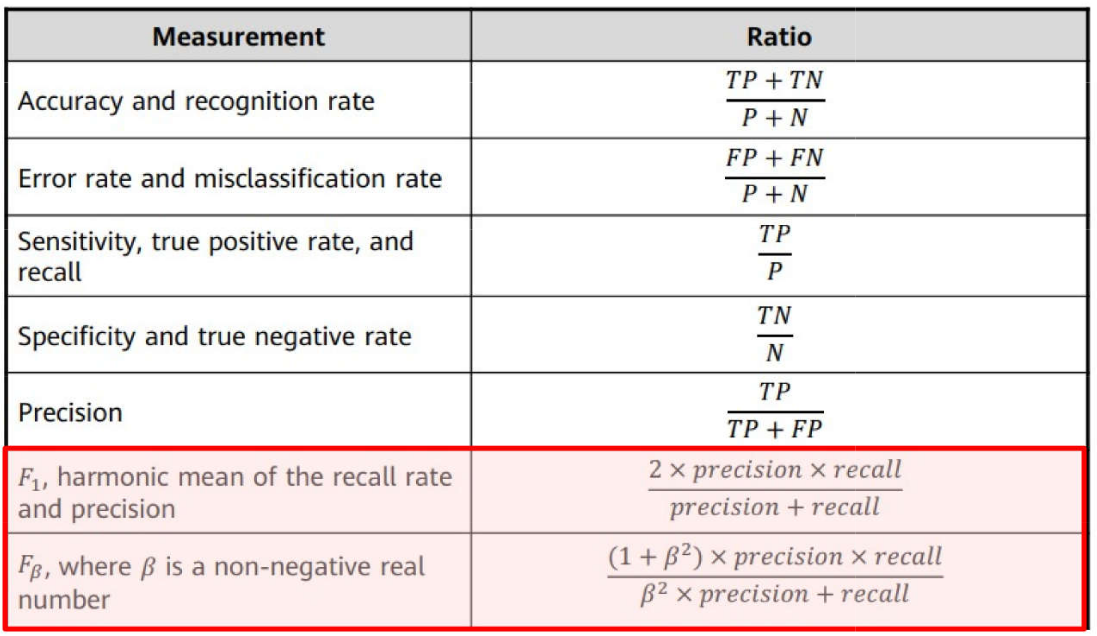
Problemas de Classificação \(\rightarrow\) Métricas: \(F_1\) Score e \(F_{\beta}\)
ML: Processo de Aprendizagem
Problemas de Classificação \(\rightarrow\) Métricas: \(F_1\) Score e \(F_{\beta}\)
O \(F_1\) Score é rigoroso, pois exige tanto alta precisão quanto alta revocação para um valor elevado. É particularmente útil em cenários onde há um custo associado a falsos positivos e falsos negativos, como em problemas de saúde ou segurança. O valor do F1 Score varia entre 0 e 1, sendo 1 a classificação perfeita e 0 indicando o pior desempenho.
A métrica \(F_{\beta}\)-Score é uma generalização do F1 Score que permite dar diferentes pesos à precisão (precision) e à revocação (recall) de acordo com a importância desejada para o problema em questão. A fórmula do \(F_{\beta}\)-Score é a seguinte:
Quando ( = 1 ), a fórmula se reduz ao F1 Score, o que dá igual importância à precisão e à revocação.
Quando ( > 1 ), a revocação é priorizada mais do que a precisão. Isso é útil em problemas onde é mais importante capturar todos os casos positivos possíveis (como em detecção de doenças).
Quando ( < 1 ), a precisão é priorizada mais do que a revocação. Isso é preferível em situações onde o custo de falsos positivos é alto (como em classificadores de spam).
ML: Processo de Aprendizagem
Problemas de Classificação \(\rightarrow\) Métricas: MCC (Matriz de Correlação de Matthews) A Matriz de Correlação de Matthews é uma métrica que leva em consideração verdadeiros positivos (TP), verdadeiros negativos (TN), falsos positivos (FP), e falsos negativos (FN). A fórmula é a seguinte:
A MCC é considerada uma das métricas mais rigorosas, pois leva em conta todos os valores da matriz de confusão. Ela é particularmente útil para conjuntos de dados desbalanceados, onde outras métricas, como a acurácia, podem ser enganosas. Um valor de MCC igual a +1 indica uma predição perfeita, 0 indica que a classificação não é melhor que o acaso, e -1 indica que todas as predições estão incorretas.
ML: Processo de Aprendizagem
Problemas de Classificação \(\rightarrow\) Métricas: Coeficiente \(\kappa\)
O coeficiente Kappa de Cohen mede a concordância entre previsões e rótulos, ajustando a proporção de concordância observada pelo acaso. A fórmula é:
\[
\kappa = \frac{P_o - P_e}{1 - P_e}
\]
onde: - \(P_o\) é a probabilidade de concordância observada, - \(P_e\) é a probabilidade de concordância esperada pelo acaso.
O Kappa é uma métrica robusta para avaliar a precisão de classificadores. Ele considera o efeito da chance, o que o torna útil para avaliar classificações em cenários com rótulos desbalanceados. Valores próximos de 1 indicam uma alta concordância, valores próximos de 0 indicam concordância esperada pelo acaso, e valores negativos indicam uma concordância inferior ao acaso.
ML: Processo de Aprendizagem
Exemplo de avaliação de desempenho de um modelo de ML
Um modelo de ML foi treinado para identificar se o objeto presente em imagens é um gato. Foram usadas 200 imagens para avaliar o desempenho do modelo, tendo sido obtida a seguinte matriz de confusão:
Deseja-se calcular as métricas de precisão, sensibilidade e acurácia do modelo.
ML: Processo de Aprendizagem
Resposta
Qual o significado desses valores?
Por que IA e ML são desejados nas empresas?
Dentre os diversos motivos e vantagens de aplicar a inteligência artificial, estão a maior eficiência, a possibilidade de automatizar processos e, consequentemente, o aumento na velocidade de conclusão de tarefas.
As aplicações que utilizam a inteligência artificial são capazes de reduzir erros e aumentar a produtividade. Por isso, as empresas que adotam a tecnologia conseguem eliminar facilmente diversos custos operacionais.
Por que IA e ML são desejados nas empresas?
No inicio de 2020 uma pesquisa on-line da McKinsey realizada com 2.360 executivos em todo o mundo já mostrava o impacto da utilização da inteligência artificial nos negócios. De acordo com o estudo, 63% dos executivos cujas empresas adotaram a IA relataram que o recurso aumentou a receita nas áreas de negócios onde é aplicada, e 44% dizem que reduziu os custos da companhia. Os aumentos de receita são relatados com mais frequência em marketing e vendas, e a diminuição dos custos na manufatura1.
Por que IA e ML são desejados nas empresas?
No entanto, inteligência artificial ainda é uma tecnologia robusta que exige que a empresa supere determinados desafios para conquistar resultados positivos com essa tecnologia.
A seguir serão detalhados 5 de alguns desses desafios:
1. Problemas de dados
Os maiores obstáculos para o lançamento de um projeto de IA são os dados. Mas especificamente, a falta de dados úteis e relevantes, livres de vieses embutidos e que não violam os direitos de privacidade.
Por que IA e ML são desejados nas empresas?
2. Custo de ferramentas e desenvolvimento
Todo investimento deve ser muito bem pensado antes de iniciar o processo de implementação e, obviamente, não é diferente com IA. É preciso elencar o que essa tecnologia pode fazer pelo seu negócio, visualizar com clareza como inteligência artificial será utilizada e atuará. Para aqueles que constroem sistemas de IA do zero, os custos de mão de obra e tecnologia podem ser altos. Este é especialmente o caso para aqueles que estão começando.
Por que IA e ML são desejados nas empresas?
3. Desafios de implementação - e escassez de competências
As implementações de IA trazem consigo diversos desafios técnicos e a maioria das organizações não possui habilidades de IA suficientes para lidar com eles de forma eficiente. Se a empresa não conta com as habilidades técnicas necessárias para incorporar IA ao seu negócio e o investimento precisa ser grande demais, uma solução é considerar contar com uma empresa parceira, para que você tenha maior controle e autonomia nesse processo.
Por que IA e ML são desejados nas empresas?
4. Desafios do processo de negócios
Integrar a IA nas funções de uma empresa é outro obstáculo. Em um processo de transformação digital, a cultura organizacional é um dos principais desafios. Além disso, contar com a estrutura adequada de hardware e software também exige muito investimento e precisa ser feito de maneira muito bem planejada.
Por que IA e ML são desejados nas empresas?
5. Uso ético e legal da inteligência artificial
A privacidade é um dos temas que empresas que utilizam novas tecnologias terão que lidar. Com as legislações de proteção de dados pessoais dos usuários já em vigor e sendo discutidos pelos governos de diversos países pelo mundo, as empresas precisam ter maturidade para cumprir as exigências legais, com o trabalho, e tratar as informações armazenadas de maneira ética.
… para finalizar - reflexão
Cada vez mais estamos vivendo na era dos algoritmos, em que as decisões que afetam nossas vidas estão sendo tomadas por modelos matemáticos. Dessa forma, é importante que o cientista tenha em mente que esses modelos em teoria deve nos conduzir a para um mundo mais justo, no qual todos devem ser julgados de acordo com as mesmas regras e o preconceito eliminado.
Essa questão é abordado no Livro “Algoritmos de destruição em massa”, no qual a autora traz diversos modelos que criam uma espiral discriminatória, como por exemplo, um estudante pobre não consegue obter um empréstimo porque o modelo matemático o considera muito arriscado (diante do endereço que ele mora), ele também é recusado na universidade que poderia tirá-lo da pobreza.
…para finalizar - vídeo…
Referências para serem utilizadas
The Elements of Statistical Learning: Data Mining, Inference and Prediction, Hastie, T., Tibshirani, R. and Friedman, J., 2nd ed., Springer-Verlag, 2009.
An Introduction to Statistical Learning: With Applications in R, James, G., Witten, D., Hastie, T. and Tibshirani, R., Springer-Verlag, 2013.
Aprendizado de máquina: uma abordagem estatística, Izbicki, R. and Santos, T. M., 2020.
Extras:
Morris, Meredith Ringel, et al. “Levels of AGI: Operationalizing Progress on the Path to AGI.” arXiv preprint arXiv:2311.02462 (2023).
Weijermars, Ruud, Umair bin Waheed, and Kanan Suleymanli. “Will ChatGPT and Related AI-tools Alter the Future of the Geosciences and Petroleum Engineering?.” First Break 41.6 (2023): 53-61.